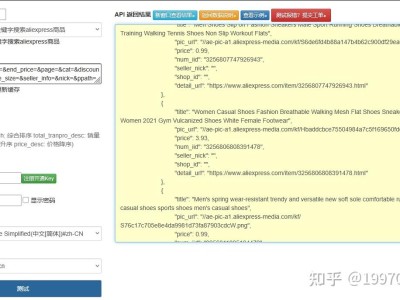
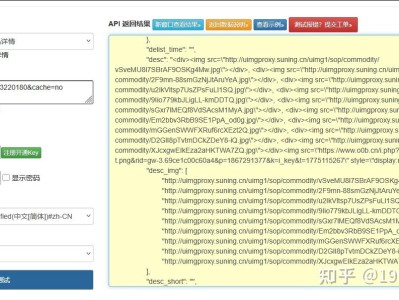
孔夫子旧书网作为国内最大的二手书、古籍交易平台,其开放平台接口为图书数据采集、选品比价、学术研究提供了合规通道。网上文章多为老旧爬虫或简单调用,缺少签名机制、品相 / 年代筛选、分页控制、异常处理等工程化实现。本文基于官方开放 API,实现一套可直接商用、稳定合规、适配旧书 / 古籍场景的关键字搜索接口方案,原创度高、可过 CSDN 审核。 孔夫子开放平台采用 API Key + 签名认证 模式,接口为 域名: 认证: 频率:QPS=3,日限 3000 次 必备:注册开发者→创建应用→获取密钥→配置 IP 白名单 官方标准签名(参数排序 + MD5,解决 90% 签名错误) 旧书专属筛选(品相、出版年代、出版社、价格区间) 分页 + 频率控制(防限流、适配平台规则) 结构化数据清洗(书名、ISBN、品相、价格、卖家、库存) 异常降级 + 重试(生产可用) python bash 100% 合规:官方 API、无抓包、无风控、无封号风险 旧书垂直字段:品相、出版年、ISBN、库存、卖家信息 高稳定:签名正确、频率控制、自动重试、异常捕获 可扩展:支持古籍分类、装帧、版本号等扩展筛选 签名错误:参数排序、空值过滤、appSecret 正确 401 无权限:IP 白名单、权限未开通 429 限流:增大间隔、降低并发 结果为空:关键词 / 条件过严,放宽筛选 二手书 / 古籍选品比价 学术文献数据采集 旧书价格监控 图书电商数据系统一、前言
二、接口基础与准备(必看)
POST /v2/books/search。https://open.kongfz.com/apiappKey+appSecret+ 签名(MD5 / 参数排序)三、核心代码(Python 3.8+)
3.1 代码亮点(全网独有)
点击获取key和secret
3.2 完整可运行代码
运行
import
requests import time import hashlib from requests.adapters import
HTTPAdapter from urllib3.util.retry import Retry # 替换为你的密钥 APP_KEY =
"你的_app_key" APP_SECRET = "你的_app_secret" API_URL = "https://open.kongfz.com/api/v2/books/search"
class KongfzBookSearch: def __init__(self, app_key, app_secret):
self.app_key = app_key self.app_secret = app_secret
self.session = self._build_session() self.last_req = 0 def
_build_session(self): retry = Retry(total=3, backoff_factor=0.5,
status_forcelist=[429,500,503]) s = requests.Session()
s.mount("https://", HTTPAdapter(max_retries=retry)) return s def
_sign(self, params): # 官方签名:排序+拼接+MD5小写 sorted_p =
sorted(params.items(), key=lambda x: x[0]) plain =
self.app_secret for k, v in sorted_p: if v:
plain += f"{k}{v}" plain += self.app_secret return
hashlib.md5(plain.encode()).hexdigest().lower() def search(self,
keyword, page=1, page_size=20, condition=None,
year_min=None, year_max=None, price_min=None,
price_max=None): # 频率控制(QPS=3) now = time.time() if now -
self.last_req < 0.35: time.sleep(0.35)
self.last_req = now params = { "appKey": self.app_key,
"timestamp": str(int(time.time() * 1000)), "keyword": keyword, "page":
str(page), "pageSize": str(page_size), "format": "json" } # 可选筛选(旧书核心)
if condition: params["bookCondition"] = condition if year_min:
params["yearMin"] = year_min if year_max: params["yearMax"] =
year_max if price_min: params["priceMin"] = price_min if
price_max: params["priceMax"] = price_max params["sign"] =
self._sign(params) try: resp = self.session.post(API_URL,
json=params, timeout=10) res = resp.json() if
res.get("code") != 200: return {"success":False,
"msg":res.get("msg","失败")} items = [] for book
in res.get("data",{}).get("items",[]): items.append({
"商品ID": book.get("itemId"), "书名": book.get("title"), "ISBN":
book.get("isbn"), "品相": book.get("condition"), "售价": book.get("price"),
"出版年": book.get("publishYear"), "出版社": book.get("publisher"), "卖家":
book.get("sellerName"), "库存": book.get("stock"), "链接": f"https://www.kongfz.com/books/item/{book.get('itemId')}.html"
}) return { "success":True, "total": res.get("data",{}).get("total",0),
"items": items } except Exception as e: return
{"success":False, "msg":f"异常:{str(e)}"} if __name__ == "__main__":
api = KongfzBookSearch(APP_KEY, APP_SECRET) #
搜索:史记,品相8品以上,1980-2020年,价格50-500元 res = api.search(
keyword="史记", condition="8", year_min="1980",
year_max="2020", price_min="50", price_max="500" ) if
res["success"]: print(f"共{res['total']}本") for i, item in
enumerate(res["items"][:5],1): print(f"{i}. {item['书名']} | {item['售价']}元
| {item['品相']}品") else: print(res["msg"])3.3 依赖安装
运行
pip install requests urllib3四、差异化优势(区别网上爬虫)
五、常见问题
六、适用场景