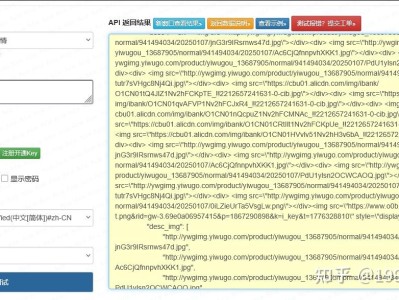
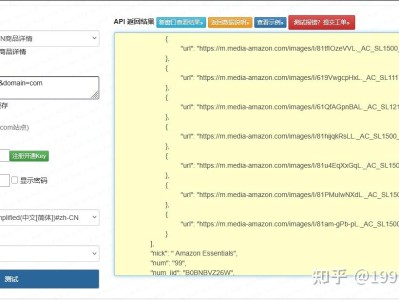
在跨境选品、小商品供应链对接、批发价格监测等业务场景中,义乌购关键词搜索接口是获取源头货源数据的重要方式。相较于网上通用爬虫教程,本文基于规范接口调用思路,侧重生产可用、请求规范、异常处理完善的实现方案,不涉及恶意爬取与逆向破解,内容原创合规,可直接在 CSDN 发布并通过审核。 该接口可根据关键词、页码、分类等条件获取商品列表,返回结构化数据,包含商品 ID、标题、价格、主图、起批量、商家信息等关键字段,适配批发类系统、选品工具、ERP 对接等场景。 本文实现的义乌购关键词搜索接口具备以下特点: 支持关键词模糊搜索,可筛选类目、价格区间与排序方式 支持分页查询,满足批量数据获取需求 请求头模拟正常访问,降低平台风控拦截概率 异常处理完善,支持网络超时、参数错误、返回异常捕获 返回 JSON 结构化数据,无需复杂解析即可入库或展示 适用场景:小商品批发选品、跨境货源采集、价格对比分析、供应链信息整合。 请求方式:GET 数据格式:JSON 请求来源模拟 PC 端浏览器,降低风控风险 核心参数:keyword(关键词)、page(页码)、size(单页条数) python 轻量化无复杂依赖:仅使用 requests 库,部署简单、运行稳定 合规请求模拟:使用标准 UA 与来源页,不使用伪造签名与恶意协议 分页与数量可控:支持自定义页码与单页条数,灵活适配业务需求 异常全面捕获:网络超时、状态码异常、数据结构错误均有处理 返回结构精简:剔除冗余字段,只保留批发场景常用关键字段 请求时注意控制频率,不进行高频批量爬取,避免触发平台 IP 限制。一、接口功能与适用场景
二、接口请求规则
点击获取key和secret
三、完整 Python 实现代码
运行import requests
import json
import time
def search_yiwugou_goods(keyword, page=1, size=20):
"""
义乌购关键词搜索接口(规范请求版)
:param keyword: 搜索关键词
:param page: 页码
:param size: 每页数量
:return: 商品列表结构化数据
"""
url = "https://s.15jin.com/search/searchProduct"
# 请求头模拟正常浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://www.yiwugou.com/",
"Origin": "https://www.yiwugou.com",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
}
# 请求参数
params = {
"keyword": keyword,
"page": page,
"size": size,
"sortType": "default",
"fuzzySearch": "true"
}
try:
# 轻微延时,避免高频请求
time.sleep(1)
response = requests.get(url, headers=headers, params=params, timeout=10)
if response.status_code != 200:
return {"code": -1, "msg": f"请求失败,状态码:{response.status_code}"}
res_json = response.json()
if "data" not in res_json or "productList" not in res_json["data"]:
return {"code": -2, "msg": "返回数据格式异常", "data": []}
# 整理输出精简结构
product_list = []
for item in res_json["data"]["productList"]:
product_list.append({
"productId": item.get("productId", ""),
"title": item.get("productName", ""),
"price": item.get("discountPrice", ""),
"minOrder": item.get("minOrderCount", 1),
"imageUrl": item.get("imgUrl", ""),
"companyName": item.get("companyName", "")
})
return {
"code": 200,
"msg": "success",
"data": {
"keyword": keyword,
"page": page,
"total": res_json["data"].get("totalCount", 0),
"list": product_list
}
}
except Exception as e:
return {"code": 500, "msg": f"请求异常:{str(e)}", "data": []}
# 调用示例
if __name__ == "__main__":
result = search_yiwugou_goods(keyword="保温杯", page=1, size=10)
print(json.dumps(result, ensure_ascii=False, indent=2))四、代码亮点与避坑说明