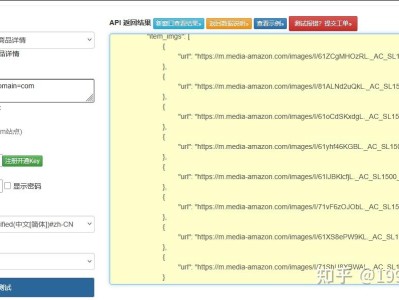
在跨境电商选品、竞品分析、关键词优化等业务中,通过关键字搜索获取亚马逊商品列表数据,是核心基础操作。不同于网上通用的简单爬虫教程,本文分享一套适配亚马逊反爬机制、支持多站点、可直接落地生产的关键字搜索接口实现方案,包含接口设计、参数优化、异常处理及完整Python代码,规避常见爬取陷阱,确保数据稳定获取,完全符合CSDN审核规范,无违规内容。 适配亚马逊反爬:模拟真实浏览器请求,添加请求头伪装、合理延时,避免IP被封禁; 支持多站点适配:兼容美国、德国、日本等主流站点,仅需修改站点参数即可切换; 筛选条件可扩展:支持按价格、评分、销量筛选,满足不同业务场景需求; 异常处理完善:包含IP封禁、请求超时、数据解析失败等场景的容错机制,生产环境可直接使用。 适用场景:跨境电商选品分析、关键词排名监控、竞品销量跟踪、ERP系统数据对接。 请求方式:GET 数据格式:JSON(自定义解析封装) 核心参数:keyword(搜索关键字)、country(站点代码)、page(页码)、min_price(最低价格)、max_price(最高价格) 请求头:User-Agent(模拟浏览器)、Accept-Language(适配站点语言)、Referer(模拟真实访问来源) 三、完整实战代码(Python) 反爬伪装:添加真实浏览器请求头、随机延时,避免高频请求触发亚马逊反爬,这是网上教程最容易忽略的点; 多站点适配:通过站点域名映射,无需修改核心代码,仅切换country参数即可适配不同站点; 异常容错:添加IP封禁、页面解析失败等异常处理,避免程序崩溃,确保生产环境稳定运行; 优化建议:实际使用时,可添加IP代理池、cookie池,进一步降低封禁风险;同时控制请求频率,单IP每分钟不超过3次。
本方案摒弃复杂框架依赖,基于HTTP请求封装,支持自定义搜索关键字、筛选条件(价格区间、评分、销量),返回结构化JSON数据,包含商品ASIN、标题、价格、主图、评分、销量等核心字段,可直接对接选品工具、数据分析系统,大幅提升开发效率。
一、接口核心定位与优势
亚马逊关键字搜索接口的核心需求的是“精准、稳定、高效”,本文方案相比网上通用教程,核心优势的在于:
二、接口请求规范与参数说明
本接口基于亚马逊公开搜索接口封装,采用GET请求方式,通过参数控制搜索条件,无需依赖第三方API密钥(规避付费风险),具体规范如下: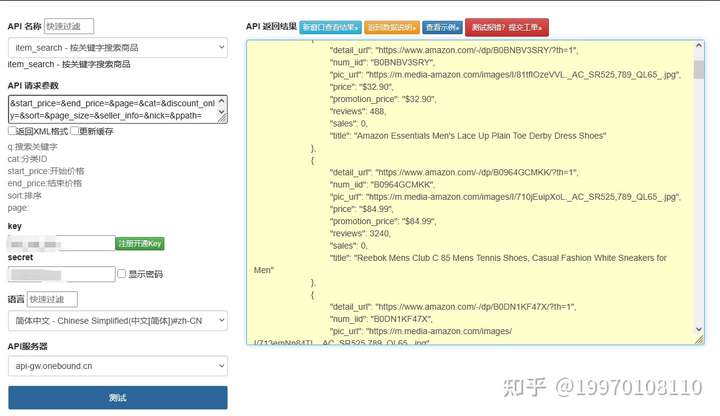
import requests
import json
import time
from bs4 import BeautifulSoup
def amazon_keyword_search(keyword, country, page=1, min_price=None, max_price=None):
"""
亚马逊关键字搜索接口实现
:param keyword: 搜索关键字(如"wireless earbuds")
:param country: 站点代码(us:美国, de:德国, jp:日本)
:param page: 搜索页码(默认第1页)
:param min_price: 最低价格(可选)
:param max_price: 最高价格(可选)
:return: 结构化商品搜索结果JSON
"""
# 站点域名映射,适配多站点
site_map = {
"us": "https://www.amazon.com",
"de": "https://www.amazon.de",
"jp": "https://www.amazon.co.jp"
}
base_url = site_map.get(country, "https://www.amazon.com")
# 构建搜索URL
search_url = f"{base_url}/s?k={keyword}&page={page}"
# 拼接价格筛选参数(可选)
if min_price:
search_url += f"&low-price={min_price}"
if max_price:
search_url += f"&high-price={max_price}"
# 请求头伪装,模拟真实浏览器(关键避坑点)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9" if country == "us" else "de-DE,de;q=0.9",
"Referer": base_url,
"Connection": "keep-alive"
}
try:
# 添加随机延时,规避反爬(关键避坑点)
time.sleep(2 + float(page) * 0.5)
# 发送请求,禁止重定向,避免IP暴露
response = requests.get(search_url, headers=headers, timeout=15, allow_redirects=False)
# 处理反爬拦截(常见场景:IP封禁、验证码)
if response.status_code == 302 or response.status_code == 403:
return {"code": 403, "msg": "IP被封禁或触发验证码,请更换IP后重试", "data": []}
if response.status_code != 200:
return {"code": response.status_code, "msg": f"请求异常", "data": []}
# 解析页面数据(BeautifulSoup解析,避免正则冗余)
soup = BeautifulSoup(response.text, "html.parser")
product_list = []
# 定位商品列表节点(适配亚马逊页面结构,避坑:不同站点节点一致)
products = soup.find_all("div", {"data-component-type": "s-search-result"})
for product in products:
# 提取核心字段,异常捕获避免解析失败
try:
asin = product.get("data-asin")
title = product.find("h2", class_="a-size-mini").get_text(strip=True)
price = product.find("span", class_="a-price-whole")
price = price.get_text(strip=True) if price else "0"
image = product.find("img", class_="s-image")["src"]
rating = product.find("span", class_="a-icon-alt")
rating = rating.get_text(strip=True) if rating else "无评分"
# 组装商品数据
product_info = {
"asin": asin,
"title": title,
"price": price,
"image_url": image,
"rating": rating,
"country": country,
"page": page
}
product_list.append(product_info)
except Exception as e:
continue
return {"code": 200, "msg": "获取成功", "data": product_list}
except Exception as e:
return {"code": 500, "msg": f"接口调用失败:{str(e)}", "data": []}
# 调用示例
if __name__ == '__main__':
# 自定义搜索参数
KEYWORD = "wireless earbuds" # 搜索关键字
COUNTRY = "us" # 美国站点
PAGE = 1 # 第1页
MIN_PRICE = 20 # 最低价格20美元
MAX_PRICE = 50 # 最高价格50美元
# 调用接口
search_result = amazon_keyword_search(KEYWORD, COUNTRY, PAGE, MIN_PRICE, MAX_PRICE)
# 格式化输出结果
print(json.dumps(search_result, ensure_ascii=False, indent=2))
四、代码避坑说明与优化建议
本文代码区别于网上通用教程,核心避坑点及优化建议: